Below are more East African mtDNA bar graphs from the Hirbo Thesis, the complementary YDNA charts can be seen in this post, along with the Boattini paper featured here, this gives us a more complete picture of East African mtDNA with a reasonable amount of detail.
Google Visualization API has been having problems for the past couple of months, so the tool tips as well as other functionalities of Google charts may not work, this post will be updated if they fix some of these issues.
With respect to some of the data points, the populations labeled with a * had their total number of samples adjusted in order for the percentages shown in Table 3.4.1 to make sense, that is, Orma has been adjusted from 20 to 21, Marakwet from 22 to 23, Pokot from 39 to 38, San from 11 to 12 and Bamoun from 18 to 20.
Showing posts with label Afrasan. Show all posts
Showing posts with label Afrasan. Show all posts
Monday, December 9, 2013
Wednesday, May 8, 2013
Another Extensive thesis on East African DNA
It was brought to my attention last week, thanks to a comment on this blog made by the user 'Umi', that another thesis on East African DNA variation was publicly available online:
Complex Genetic History of East African Human Populations
This is also an extensive thesis with a wealth of information akin to Plaster's thesis, the primary differences being that this one was more focused on parts of East Africa that are found further to the South of Ethiopia, and in addition to uni-parental analysis, it also included some Autosomal model-based inference, albeit of quite low resolution in today's standards; 848 microsattelites and 479 indels (refer to Tishkoff et al. 2009 for marker details).
Due to the extensive nature of the report I haven't had a chance to cover its entire scope, instead, for starters, I have first focused on the YDNA data by creating a relative frequency chart from the results reported in Fig. 3.3.2.
Several things to initially point out here,
- The report outlines the discovery of 4 new SNPs, TL1-4. The first two were found in Haplogroup B and downstream from B-M150 and B-M112 respectively. The last two, TL3 and TL4, were found in haplogroup E and downstream from E-U174 and E-V32 respectively. Incidentally, the fourth SNP that is under E-V32, TL4, could potentially be the same as Z808/Z809 as identified recently by the geneological community, however, as the report does not give the Y-Chromosome location of the SNP in a NCBI Build 36/37 format, this can not be verified, at least by me, at the moment.
- A couple of the frequency results in Fig. 3.3.2 do not add up, in particular, the frequency results for the Boni and the Baggara, but also to a lesser extent for the Kanuri and Teita. I have labeled the missing frequency results with a “?” in the relative charts for those specific populations.
- The Burji and Konso are labeled as being only from Kenya throughout the report, however most Burji are from Ethiopia, and the Konso are exclusively found in Ethiopia, I have reflected this in the charts.
- STR data is not readily available to perform TMRCA estimates on, however, some TMRCA results are reported using Zhivotovsky's rates in Table 3.3.1, nevertheless, these are estimates only for different lineages found in the dataset for all the samples and not necessarily comparing TMRCAs in the different populations under study.
- J-M62, while a subclade of J-M267, is not the main subclade of J-M267 found in East Africa, that would be J-P58, therefore, the results for J-12f2.1 (x M62, M172) reported, may after all be, or largely include, J-P58 lineages, off-course those results could also include variants of J-M267 other than J-P58 and J-M62 as well since the SNP was not directly tested.
- E-P2* lineages are abundantly found (> 30%) in the Konso, Burji and Mbugwe, however on closer examination and correlation with current data, these could be E-M329, E-V38* or even E-M215*, as none of these SNPs were directly tested. Genuine E-P2* lineages would be positive for E-P2 and negative for V38 and M215 (See Trombetta et al. 2011)
- Similarly, the E-M35* lineages reported could be members of relatively newly discovered lineages of E-Z830*( See this post for details), or some of the untested variantes of E-M35, i.e. E-V42, V92 and maybe even E-V68 (x M78)
Wednesday, May 1, 2013
Analyzing YDNA J lineages in Ethiopian linguistic groups
The extensive YDNA dataset found in the Plaster paper has a total of 691 YDNA lineages that belong to haplogroup J, although there is no more detailed SNP resolution reported for most of these lineages, it is safe to assume, from previous data on Ethiopia, that a vast majority of them would belong to J1-M267. There is a limited set of STR data that accompanies these lineages as well, namely only for the markers; 19, 388, 390, 391, 392 and 393.
According to the report, J lineages are proportionally found higher in Semitic speakers in Ethiopia, ~21% ,followed by Omotic speakers at ~ 12% and Cushitic speakers at ~ 8%. Out of the 691 YDNA J lineages reported, 259 were Semitic speakers, 266 spoke some type of Omotic language and most of the remainder spoke Cushitic languages.
According to the report, J lineages are proportionally found higher in Semitic speakers in Ethiopia, ~21% ,followed by Omotic speakers at ~ 12% and Cushitic speakers at ~ 8%. Out of the 691 YDNA J lineages reported, 259 were Semitic speakers, 266 spoke some type of Omotic language and most of the remainder spoke Cushitic languages.
Monday, February 4, 2013
A speculative superimposition of E-M35 variants onto Afroasiatic.
Here is a speculative superimposition of the variants of YDNA E-M215/M35 (E1b1b/1) onto an Afroasiatic internal classification, Lionel Bender's (1997) classification.

The red question marks represent a less unsure fit.

Monday, January 7, 2013
East African mtDNA variation has implications on the origin of Afroasiatic
The Dienekes' Anthropology Blog shows a new paper on East African mtDNA with implications for the origin of Afroasiatic, namely with the citing: "making the hypothesis of a Levantine origin of AA unlikely", unfortunately I do not have access to the paper, I would greatly appreciate if anyone has access to it to please send me a copy here: ethiohelix@gmail.com.
Here is the abstract and the link:
mtDNA variation in East Africa unravels the history of afro-asiatic groups
UPDATE: Ok, got it, this was a nice little article to read, however with respect to the implications of East African mtDNA variation on the origin of Afroasiatic, it did not offer nothing really substantially new, in terms of material evidence, that any reasonable person that has read up on this subject a little bit would not have known beforehand, namely:
Concerning the third point, i.e., the place of origin of AA (EA or the Levant), our results do not allow us to make conclusive statements. Indeed, coalescent simulations of different genetic parameters (Supporting Information Fig. 4) according to the two mentioned hypotheses show that—even assuming complete correlation between languages and mtDNA variability—their confidence intervals largely overlap. Thus, we limit ourselves to the following observations. First, EA shows the highest levels of nucleotide diversity among the studied populations with a decreasing cline towards NA and the Levant (Supporting Information Fig. 1 and Supporting Information Table 1). This is true not only for the Ethiopian cluster A, but also, and especially, for groups belonging to clusters B1 and B2. Second, EA hosts the two deepest clades of AA, Omotic and Cushitic. These families are found exclusively in EA, while the presence of Semitic in this area is much more recent. Third, cluster C – collecting Berber- and Semitic-speaking populations from NA and the Levant – shows only modest signals of admixture with clusters A and B (Fig. 2, Supporting Information Table 1). None of these points,
taken by itself, is conclusive, but undoubtedly the hypothesis of origin of AA in EA is the most parsimonious one, if compared to the Levant.
It did also have some very nicely made contour maps for EA, as well as detailed mtDNA haplogroup assignments for some 30 or so East African groups, which I will make an interactive chart for within the next couple of days.
UPDATE2 (01/08/2013): mtDNA haplogroups (46) in 31 groups.
A note on the sources for the samples listed above:
Here is the abstract and the link:
Abstract
East Africa
(EA) has witnessed pivotal steps in the history of human evolution. Due
to its high environmental and cultural variability, and to the long-term
human presence there, the genetic structure of modern EA populations is
one of the most complicated puzzles in human diversity worldwide.
Similarly, the widespread Afro-Asiatic (AA) linguistic phylum reaches
its highest levels of internal differentiation in EA. To disentangle
this complex ethno-linguistic pattern, we studied mtDNA variability in
1,671 individuals (452 of which were newly typed) from 30 EA populations
and compared our data with those from 40 populations (2970 individuals)
from Central and Northern Africa and the Levant, affiliated to the AA
phylum. The genetic structure of the studied populations—explored using
spatial Principal Component Analysis and Model-based clustering—turned
out to be composed of four clusters, each with different geographic
distribution and/or linguistic affiliation, and signaling different
population events in the history of the region. One cluster is
widespread in Ethiopia, where it is associated with different
AA-speaking populations, and shows shared ancestry with Semitic-speaking
groups from Yemen and Egypt and AA-Chadic-speaking groups from Central
Africa. Two clusters included populations from Southern Ethiopia, Kenya
and Tanzania. Despite high and recent gene-flow (Bantu, Nilo-Saharan
pastoralists), one of them is associated with a more ancient AA-Cushitic
stratum. Most North-African and Levantine populations (AA-Berber,
AA-Semitic) were grouped in a fourth and more differentiated cluster. We
therefore conclude that EA genetic variability, although heavily
influenced by migration processes, conserves traces of more ancient
strata. Am J Phys Anthropol, 2013. © 2013 Wiley Periodicals, Inc.
mtDNA variation in East Africa unravels the history of afro-asiatic groups
UPDATE: Ok, got it, this was a nice little article to read, however with respect to the implications of East African mtDNA variation on the origin of Afroasiatic, it did not offer nothing really substantially new, in terms of material evidence, that any reasonable person that has read up on this subject a little bit would not have known beforehand, namely:
Concerning the third point, i.e., the place of origin of AA (EA or the Levant), our results do not allow us to make conclusive statements. Indeed, coalescent simulations of different genetic parameters (Supporting Information Fig. 4) according to the two mentioned hypotheses show that—even assuming complete correlation between languages and mtDNA variability—their confidence intervals largely overlap. Thus, we limit ourselves to the following observations. First, EA shows the highest levels of nucleotide diversity among the studied populations with a decreasing cline towards NA and the Levant (Supporting Information Fig. 1 and Supporting Information Table 1). This is true not only for the Ethiopian cluster A, but also, and especially, for groups belonging to clusters B1 and B2. Second, EA hosts the two deepest clades of AA, Omotic and Cushitic. These families are found exclusively in EA, while the presence of Semitic in this area is much more recent. Third, cluster C – collecting Berber- and Semitic-speaking populations from NA and the Levant – shows only modest signals of admixture with clusters A and B (Fig. 2, Supporting Information Table 1). None of these points,
taken by itself, is conclusive, but undoubtedly the hypothesis of origin of AA in EA is the most parsimonious one, if compared to the Levant.
It did also have some very nicely made contour maps for EA, as well as detailed mtDNA haplogroup assignments for some 30 or so East African groups, which I will make an interactive chart for within the next couple of days.
UPDATE2 (01/08/2013): mtDNA haplogroups (46) in 31 groups.
The Dinka Samples are from Krings etal. (1999)
The Sudan and Ethiopia Samples are from
Soares et al. (2011)
The Tigrai, Amhara, Gurage, Oromo and
Yemeni1 Samples are from Kivisild et al. (2004)
The Beta Israel Samples are from Beharet al. (2008)
The Ethiopian Jewish Samples are from
Non et al. (2011)
The Somali Samples are from Soares et al. (2011) and Watson et al. (1997)
The Daasanach and Nyangatom Samples are
from Poloni et al. (2009)
The Turkana2 Samples are from Poloni et al. (2009) and Watson et al. (1997)
The Nairobi Samples are from
Brandstatter et al. (2004)
The Kikuyu Samples are from Watson et al. (1997)
The Hutu Samples are from Castrì etal. (2009)
The Iraqw Samples are from Knight etal. (2003)
The Burunge and Turu Samples are from
Tishkoff et al. (2007)
The Datoga and Sukuma Samples are from Tishkoff et al. (2007) and Knight etal. (2003)
All the remaining samples: Dawro Konta,
Ongota, Hamer, Rendille, Elmolo, Luo, Maasai, Samburu and Turkana are new and sampled along with this study.
Tuesday, September 18, 2012
Berber YDNA
Decent resolution composite Berber YDNA from The Berber and the Berbers, Genetic and linguistic diversities, Jean-Michel Dugoujon et. al (2009)
Update: With respect to R-P25 (x M269) found in the Siwa and Mozabite Berbers, there is an even more exact breakdown of the lineage in this table from another publication using the same samples as above. It shows for the Siwa Berbers, the 26.9% of R-P25 (x M269) being further resolved to 23.7 % R-V88* (x M18, V8, V35, V69) plus 3.2% R-V69 (a branch of R-V88), similarly for the Mozabite Berbers, the 3% of R-P25 (x M269) is all resolved to R-V88* (x M18, V8, V35, V69). |
| Phylogeny of the 29 biallelic MSY markers (in bold) tested |
Friday, June 22, 2012








Friday, March 16, 2012
Introducing Yemenis into the Afrasan dataset.
This is about an observation made when
I introduced the Yemenis (from Behar (2010)) into an ADMIXTURE analysis of the Afrasan Dataset (x Mozabites).
Thursday, March 8, 2012
Afrasans in a Genome-Wide context.
A subset of the Intra-African dataset I
have includes Afrasans, or Afroasiatic speakers. Afroasiatic is
typically divided into 6 major categories or groups; Semitic, Berber,
Egyptian, Chadic, Cushitic and Omotic. A 7th, but nearly extinct group, known
as Ongota is contentious, but is by some included as its own branch
within the Afroasiatic phylum. All of these Language groups, with
the exception of Semitic, are exclusively found in Africa. The 211
Afrasan samples in the dataset belong to 4 or 5 of those groups mentioned,
depending on how one accounts for any language shifts (that is shifts
within the wider Afrasan phylum) that might have occurred. A rough
table is shown below associating the 211 samples with current, and in
some cases previously spoken language or language groups of
Afroasiatic.

In general, Afroasiatic is thought to
have emerged somewhere in the North Eastern section of Africa,
anywhere from Ethiopia to Southern Egypt, in the genetic (Autosomal)
sense, this area can perhaps be viewed as where
such populations inhabiting that area in Africa, lie along a diagonal axis of the C1 vs C3 Intra- African MDSplot (at ~
34°
from the horizontal), as highlighted below:
MDS plots
After extracting the 211 AA speaking
samples from the 1065 sample African Dataset, I performed an MDS Analysis on
it as seen below.


Component 1 separates
Berber/Semitic/Egyptian speakers from Chadic speakers, with Ethiopian
Semitic/Cushitic speakers plotting somewhere in between, but closer
to the former in this separation. Component 2, separates Ethiopians+Egyptians from the rest.

Component 3 Separates the Mozabites
from the Rest, with Ethiopians again retaining an intermediate
position.
Model Based Analysis
The Logical value for a K selection
would be 6, i.e. equivalent to the number of known Afroasiatic
subgroups, however, since Omotic speakers are not present in the
Dataset, I went ahead and run a K=5 unsupervised ADMIXTURE Analysis
for the Afrasan Dataset.
The K=5 ADMIXTURE run produced the
following FST distances,

The biggest separation for both Axis is
for the cluster I nicknamed Cushitic, while the Berber, Semitic and
Mozabite clusters appear pretty close, with the Mozabites looking a
bit isolated.
The Median proportions for the clusters
can be seen below.

The fact that the mozbites formed their
own cluster, is intriguing, although one would suspect that
inbreeding may play a role, since it can also be seen how the Mozabites
cluster away from other North Africans in the 3D MDS plot, almost
forming their own group.
Therefore, to see what this analysis would
look like without the Mozabites, I took all 27 of them out, leaving
me with 184 AA speaking samples.
I repeated the same analysis as above on the
newer Dataset.
MDS Plots



Components 1 and 2 behaved the same way
as when the Mozabites were included, Component 3 however, without the
Mozabites, separates Berber and Cushitic speakers from the rest to almost the same
degree, unlike when the Mozabites were included.
Model Based Analysis

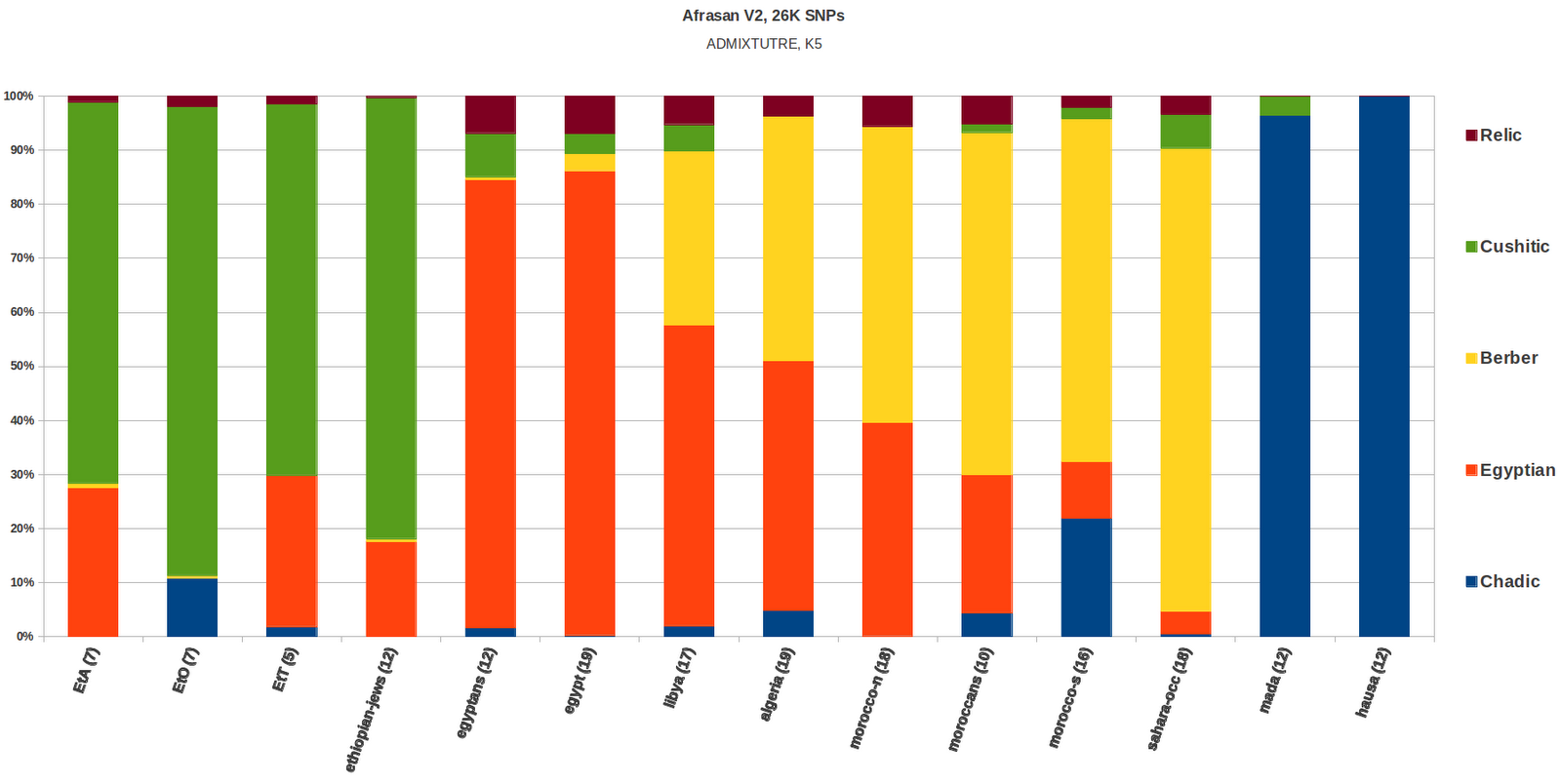
This second iteration of the Afrasan dataset that did not include the Mozabites
created a Cushitic, Chadic, Berber and Egyptian clusters, with a 5th
cluster which looked like a relic that is present in trace amounts in
all the Afrasan samples except the Mada and Hausa. The Egyptian
cluster is also found in highland Ethiopians, it also shows a more frequent occurrence of
high Standard Deviation relative to all the other clusters;

So the Egyptian cluster looks like it
gives less of a linguistic signal than the other clusters, it could
potentially be inclusive of a Semitic signal as well as maybe other
types of non-Afroasiatic Eurasian affinities.
It would be of great interest to see where
Omotic speakears would fit into this analysis.
Subscribe to:
Posts (Atom)


{kind=link}
{kind=link}