A subset of the Intra-African dataset I
have includes Afrasans, or Afroasiatic speakers. Afroasiatic is
typically divided into 6 major categories or groups; Semitic, Berber,
Egyptian, Chadic, Cushitic and Omotic. A 7th, but nearly extinct group, known
as Ongota is contentious, but is by some included as its own branch
within the Afroasiatic phylum. All of these Language groups, with
the exception of Semitic, are exclusively found in Africa. The 211
Afrasan samples in the dataset belong to 4 or 5 of those groups mentioned,
depending on how one accounts for any language shifts (that is shifts
within the wider Afrasan phylum) that might have occurred. A rough
table is shown below associating the 211 samples with current, and in
some cases previously spoken language or language groups of
Afroasiatic.

In general, Afroasiatic is thought to
have emerged somewhere in the North Eastern section of Africa,
anywhere from Ethiopia to Southern Egypt, in the genetic (Autosomal)
sense, this area can perhaps be viewed as where
such populations inhabiting that area in Africa, lie along a diagonal axis of the C1 vs C3 Intra- African MDSplot (at ~
34°
from the horizontal), as highlighted below:
MDS plots
After extracting the 211 AA speaking
samples from the 1065 sample African Dataset, I performed an MDS Analysis on
it as seen below.


Component 1 separates
Berber/Semitic/Egyptian speakers from Chadic speakers, with Ethiopian
Semitic/Cushitic speakers plotting somewhere in between, but closer
to the former in this separation. Component 2, separates Ethiopians+Egyptians from the rest.

Component 3 Separates the Mozabites
from the Rest, with Ethiopians again retaining an intermediate
position.
Model Based Analysis
The Logical value for a K selection
would be 6, i.e. equivalent to the number of known Afroasiatic
subgroups, however, since Omotic speakers are not present in the
Dataset, I went ahead and run a K=5 unsupervised ADMIXTURE Analysis
for the Afrasan Dataset.
The K=5 ADMIXTURE run produced the
following FST distances,

The biggest separation for both Axis is
for the cluster I nicknamed Cushitic, while the Berber, Semitic and
Mozabite clusters appear pretty close, with the Mozabites looking a
bit isolated.
The Median proportions for the clusters
can be seen below.

The fact that the mozbites formed their
own cluster, is intriguing, although one would suspect that
inbreeding may play a role, since it can also be seen how the Mozabites
cluster away from other North Africans in the 3D MDS plot, almost
forming their own group.
Therefore, to see what this analysis would
look like without the Mozabites, I took all 27 of them out, leaving
me with 184 AA speaking samples.
I repeated the same analysis as above on the
newer Dataset.
MDS Plots



Components 1 and 2 behaved the same way
as when the Mozabites were included, Component 3 however, without the
Mozabites, separates Berber and Cushitic speakers from the rest to almost the same
degree, unlike when the Mozabites were included.
Model Based Analysis

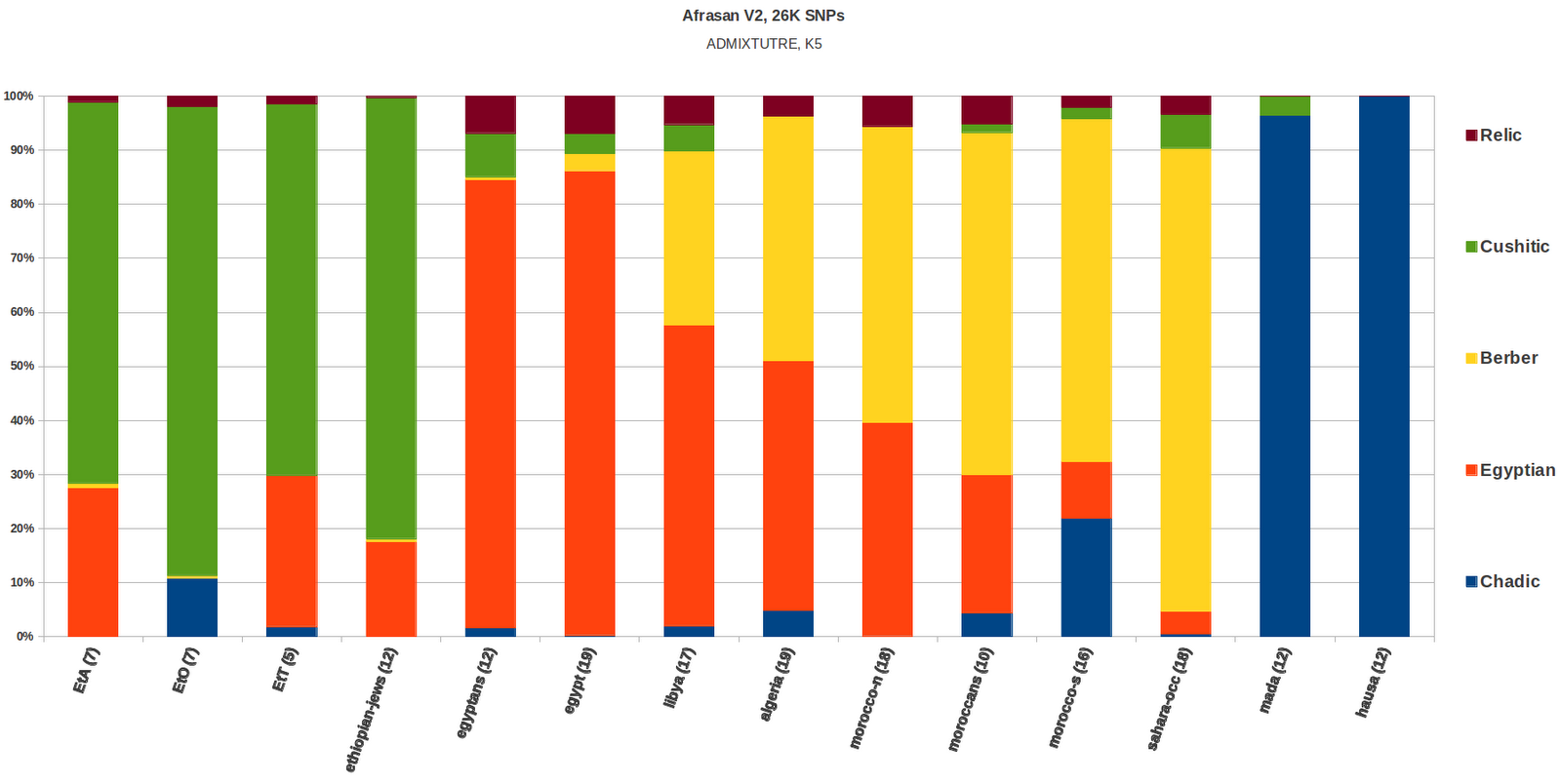
This second iteration of the Afrasan dataset that did not include the Mozabites
created a Cushitic, Chadic, Berber and Egyptian clusters, with a 5th
cluster which looked like a relic that is present in trace amounts in
all the Afrasan samples except the Mada and Hausa. The Egyptian
cluster is also found in highland Ethiopians, it also shows a more frequent occurrence of
high Standard Deviation relative to all the other clusters;

So the Egyptian cluster looks like it
gives less of a linguistic signal than the other clusters, it could
potentially be inclusive of a Semitic signal as well as maybe other
types of non-Afroasiatic Eurasian affinities.
It would be of great interest to see where
Omotic speakears would fit into this analysis.


{kind=link}
{kind=link}
They were supposed to release some data of Omotic groups (and additional Amhara samples) here ftp://ftp.ncbi.nlm.nih.gov/dbgap/studies/ under accession #phs000449 but it still hasn't been uploaded. My bet is that in global context they may be somewhere intermediate between the Oromo and Maasai samples, and in regional context they may be quite distinct and perhaps make their own cluster. We'll see.
ReplyDeleteYeah, I've been checking on that since you notified me last time, but haven't seen any thing. Do you think it would be in .bed format or some other type, like Behar's Series Matrix files, which is a pain in the .. to import into PLINK. I also hope these 26K SNPs I have would intersect well with the Dataset they would be eventually releasing with out thinning it out too much more....
DeleteUsually it's in .ped or .bed format. If this isn't the case I'll find a way to convert it. IIRC, the data was based on the 1 mil illumina chip, so it's going to overlap with most datasets (affymetrix data generally has less dataset overlap).
DeleteWell they presumably do have a .ped or .bed format or otherwise they wouldn't have been able to do this:
Delete"All of the 47 samples had high call rates (> 95%), and the software package PLINK [37] was used to estimate relatedness among individuals"
I do hope they upload the files in that same format and hopefully sooner rather than later, BTW these are locations and quantities of the samples:
- 28 male individuals living in the Amhara region in Debele, which is near Debre Birhan
-nine individuals living in Gieza (the Aari)
-ten individuals living in Dimeka (the Hamer)
Those look like interesting samples indeed.
ReplyDeletePS. You should check out this new software, perhaps you could try it out on the intra-african dataset: http://precedings.nature.com/documents/6956/version/1
http://code.google.com/p/treemix/
I've always though it was rather strange that so many genetic studies of North Africans indicate a rather miniscule genetic input from Tropical Africans. Considering people from South the Sahara have consistebtly coexisted with those in the Sahara. The people share a language family (that probably originate in the Horn of Africa) and still the genetic affinity appears small. Any insight into that at all?
ReplyDelete